为什么 Agent 需要一个操作系统
从一个数学事实说起
一个 10 步的 AI Agent,每一步有 90% 的成功率。端到端的成功率是多少?
大多数人会猜 80%,甚至 70%。实际是 34.9%。30 步呢?4.2%。
我第一次算出来的时候以为哪里搞错了。反复验证之后才接受这个现实——每一个在生产环境中跑过 Agent 的工程师都会撞上这堵墙。模型在变强,Claude 4 的推理能力已经接近人类专家,GPT-5 在编码基准上屡破纪录,但可靠性的数学不会因为模型变聪明而改变。
Agent 的每一步——读取文件、调用工具、解析结果、做出决策——都是一个故障点。这些故障点是相乘的,不是相加的。Agent 越复杂,失败概率不是线性增长,而是指数增长。
归根结底这是个基础设施问题。
98.4% 的代码不是在调模型
2026 年 3 月,Claude Code 的 TypeScript 源码被公开分析。VILA-Lab(新加坡国立大学)发表了一篇系统性的逆向工程研究,发现了一个有意思的数字:
在 Claude Code 的 51.2 万行代码中,只有约 1.6% 是 AI 决策逻辑。剩余的 98.4% 是确定性基础设施——权限门控、上下文管理、工具路由和恢复逻辑。
Claude Code 是 2025-2026 年最具影响力的 Coding Agent 产品之一。它能自主读取整个代码库、制定修改计划、编辑多个文件、运行测试、修复错误,然后提交代码。从外面看是"会编程的 AI",但打开来看,是一台精密的状态机。
模型调用只是其中一个环节——发出 HTTP 请求,等待流式响应,解析 tool_use 块。真正的工程量在别处:
- 5 层上下文压缩管线:在每次模型调用之前,依次运行预算削减、片段裁剪、微压缩、上下文折叠和自动摘要,确保对话历史不超出窗口限制
- 双阶段安全分类器(YOLO):每个工具调用先经过 64 token 的快速扫描,可疑的进入 4,096 token 的完整推理判断——允许、拒绝或询问用户
- 多 Agent 协调系统:子 Agent 通过磁盘文件进行消息传递(~/.claude/work/ipc/),500 毫秒轮询,Leader-Worker 架构
- 工具执行管线:43 个工具实现,流式执行器在 API 响应完成之前就开始执行工具调用,最多 10 个并发
- 9 步处理流水线:设置解析 → 状态初始化 → 上下文组装 → 5 层压缩 → 模型调用 → 工具分派 → 权限门控 → 工具执行 → 停止条件判断
这是一个运行时系统。一个真正的、带内存管理和中断处理的运行时。

为什么 Code Agent 是最难的 Agent
一个客服 Agent 说错了一句话,最坏的后果是什么?用户不满意,重新生成一次回答。
一个 Code Agent 写错了一行代码,后果可能严重得多。2026 年 5 月,一个使用 Devin 的团队报告了一个案例:Agent 在修复一个数据库迁移脚本时,错误地执行了 DROP TABLE 然后试图重建表结构。测试环境的数据没了。幸好不是在生产环境。
Code Agent 的独特困难可以归纳为六个维度。理解这六个维度,才能理解为什么 Code Agent 需要的基础设施比任何其他 Agent 都重。
不可逆的副作用
聊天 Agent 的输出是文本——错了可以重来。搜索 Agent 返回错误的结果——换个关键词再搜。但 Code Agent 的每一步操作都在修改现实世界的状态:写入文件、执行 Shell 命令、修改配置、安装依赖。
这些操作不是幂等的。rm -rf node_modules && npm install 可能安装出不同版本的依赖。git rebase 可能产生无法自动解决的冲突。一个错误的 sed 命令可能静默地破坏一个二进制文件。
Claude Code 为此投入了 43 个工具实现和双阶段安全分类器——每一个工具调用都可能改变世界,所以每一个都要过安检。
上下文的饥渴
对话 Agent 处理短文本,用户消息通常不超过 200 个 token。RAG Agent 检索文档片段,每段几百 token。
Code Agent 呢?读一个源文件就可能消耗 5,000 token。一个中等规模的重构任务需要读 20 个文件——10 万 token 光读取就花完了,还没开始推理。然后工具输出(编译错误、测试结果、grep 搜索)还会继续吞噬上下文。消耗速度是对话 Agent 的 10 到 50 倍。
上下文压缩对 Code Agent 不是锦上添花,是生存问题。没有压缩引擎的 Code Agent,在第三个文件就会撞上窗口限制。Claude Code 的 5 层压缩管线、Kairo 的 6 阶段压缩引擎,存在的理由就是这个。
隐形的依赖图
自然语言没有编译器。你改了一段话中的一个词,不会导致另一段话"报错"。
但代码有依赖图。你改了文件 A 中的一个方法签名,文件 B、C、D 中的所有调用者都会编译失败。更隐蔽的是:你改了一个接口的语义(不改签名),下游的代码会静默地产生错误行为——不报错,但结果是错的。
Agent 无法直接"看到"依赖图。它必须通过工具调用去发现:运行编译器、执行 grep 搜索、触发测试。每一次发现都消耗上下文。这里有一个结构性的恶性循环:了解影响范围本身就在消耗了解影响范围所需的资源。
我还没在其他 Agent 领域见过这种矛盾。
验证的死亡螺旋
客服 Agent 生成了回答,任务就结束了。Code Agent 写完代码后必须验证——编译通过了吗?测试跑过了吗?linter 有警告吗?类型检查呢?
每一轮验证:
- 消耗 token——编译输出、测试报告、错误堆栈本身就是大量文本
- 可能暴露新问题——修了 A 文件的编译错误,B 文件的测试又挂了
- 触发新一轮修复——修复 B 文件,又需要编译和测试
修复 → 验证 → 发现新问题 → 修复 → 验证,每一轮都在吞噬有限的上下文窗口。一个需要 5 轮修复的任务,光验证输出就可能消耗 3 万 token。
Claude Code 能在复杂重构任务中保持有效,很大程度上靠的是它的压缩管线能在验证循环中持续回收上下文空间。没有这个能力的 Agent,在第二轮验证就开始"忘记"自己在做什么。
长程一致性
"给这个 Spring Boot 应用添加 JWT 认证"——听起来简单,实际上需要:
- 添加依赖到 pom.xml
- 创建 JwtTokenProvider 类
- 创建 JwtAuthFilter
- 配置 SecurityFilterChain
- 创建 AuthController
- 修改现有的 Controller 添加 @Authenticated 注解
- 编写测试
- 更新 application.yml
8 个文件、50+ 次工具调用。Agent 必须在第 47 步(修改最后一个 Controller)时,仍然记得第 3 步(JwtAuthFilter)中使用的 header 名称是 "Authorization" 而不是 "X-Auth-Token"。
任何不一致——哪怕只是一个命名差异——都会导致运行时错误。而且这些错误往往不在编译时暴露,只在集成测试甚至生产环境中才冒出来。对话 Agent 不需要这种一致性,搜索 Agent 每次查询都是独立的,只有 Code Agent 需要在 50 步的跨度上维持架构级别的语义一致性。
权限悖论
最后一个困难:Code Agent 必须拥有危险的权限才能有用。
一个只读的 Code Agent 几乎没有价值——你需要它写文件、运行命令、安装依赖。偏偏这些权限同时赋予了它破坏的能力:删除文件、执行任意 Shell 命令、下载恶意包。
这个矛盾没有完美解:
- 给予充分权限 → Agent 有用但危险
- 限制权限 → Agent 安全但无用
- 每次询问用户 → 安全且有用,但极其低效
Claude Code 的做法是三态权限模型(ALLOWED / ASK / DENIED)配合 Hook 系统。Kairo 在此基础上扩展到 30 个生命周期点 × 5 种决策值(CONTINUE / MODIFY / SKIP / ABORT / INJECT),提供更细粒度的治理。说实话,我不确定这个粒度是否过度设计——目前用到的组合远没有理论上那么多,但我倾向于先把接口留出来,后续再看哪些可以收敛。
理解了这六个维度,大概就能理解为什么 Code Agent 的基础设施需求远超其他类型的 Agent。它不只是需要一个更好的 prompt。它需要内存管理、进程隔离、中断处理、安全策略、故障恢复。
它需要一个操作系统。
Linux 内核的启示
把时间倒回五十年。
1991 年,Linus Torvalds 发布了 Linux 内核的第一个版本。那时候操作系统的中枢——进程调度、内存管理、文件系统——只有几千行代码。到了 2024 年,Linux 内核膨胀到 2800 万行,其中设备驱动占了 70%。
操作系统最根本的"智能"——调度算法、页面置换策略、中断处理——在整个系统中的占比微乎其微。绝大多数代码是在处理与现实世界的接口:磁盘驱动、网络协议、USB 设备、图形加速。
回头看 Claude Code 的 1.6% vs 98.4%,结构是一样的。
模型是 Agent 的"CPU"——负责推理和决策。但一个只有 CPU 的系统什么也做不了。它需要内存管理(上下文压缩),需要中断处理(Hook 生命周期),需要设备驱动(工具执行器),需要文件系统(持久化记忆),需要安全机制(权限与护栏),需要进程间通信(多 Agent 协调)。
我觉得这不只是比喻,是同构——两个领域面对的问题空间高度重合:有限资源的调度、不可信输入的防御、多任务的协调、故障的隔离与恢复。当然也有人觉得我在强行类比,最初给同事看这个映射的时候确实被嘲笑过。不过后面会看到,这个类比在实际设计中的指导意义超出了我自己的预期。
行业地图:五种哲学
2026 年的 Coding Agent 市场已经形成了清晰的分野。每种产品代表一种对"Agent 应该是什么"的不同回答。
Claude Code 是最接近"操作系统"思路的产品。终端原生,工具丰富,Hook 系统提供行为定制,子 Agent 架构提供上下文隔离,5 层压缩管线管理有限的上下文窗口。短板也明确:绑定 Anthropic 模型、session 管理依赖云端。
Cursor 选择了"IDE 优先"的路线。AI 能力嵌入编辑器,开发者始终在主循环中。它的强项是即时反馈和流畅体验——你写代码,AI 实时补全和建议。3.0 版本加入了 8 个并行后台 Agent,但缺少可编程的 Hook 系统,也没有公开的压缩策略。更像一个增强型编辑器。
Devin 走向了另一个极端——完全自治。给它一个 Jira ticket,它在云端 VM 中自主工作:读代码、写代码、运行测试、提交 PR。你只看结果。高价定位对应着最高的自主性,但也意味着你交出了控制权。
LangChain / Spring AI 解决的是不同层面的问题。它们是 API 封装层——帮你连接不同的模型,管理 prompt 模板,提供 RAG 管线。但它们不管理 Agent 的上下文生命周期,不检测执行循环,不提供安全护栏,不处理级联失败。
Google ADK 提供了多语言(Python / Java / Go / TypeScript)Agent 框架和 A2A 协议标准,但深度绑定 Gemini 生态,在上下文压缩和生产安全方面的投入相对有限。
| 维度 | Claude Code | Cursor | Devin | LangChain4j | Spring AI |
|---|---|---|---|---|---|
| 开源 | 源码可读 | 否 | 否 | 是 | 是 |
| 模型选择 | 仅 Claude | 多模型 | 专有模型 | 多模型 | 多模型 |
| 自托管 | 否 | 否 | 否 | 是 | 是 |
| 上下文压缩 | 5 层管线 | 未公开 | 未公开 | 无 | 无 |
| 循环检测 | 有 | 未公开 | 未公开 | 无 | 无 |
| 治理钩子 | 29 个事件 | 无 | 无 | 无 | 无 |
| 多 Agent | Leader-Worker | 后台 Agent | 单 Agent | 无内置 | 无内置 |
| 运行时语言 | TypeScript | TypeScript | Python | Java | Java |
| 定位 | Agent 运行时 | AI IDE | 自治开发者 | API 封装 | API 封装 |
从这张表能看出一个结构性的空白:在 Java 生态中,没有人在做那 98.4% 的工作。LangChain4j 和 Spring AI 帮你调模型,但谁帮你管理上下文窗口?谁帮你检测 Agent 是否陷入了死循环?谁帮你在模型 API 超时时优雅降级?
当然,"没有人做"不一定意味着"应该做"。也许 Java 生态的开发者不需要这些东西,也许他们已经用其他方式解决了。我的判断是需要,但这个判断是否正确,最终要靠实际使用来验证。
操作系统的同构
下面这张映射表,是我从构建 Kairo 的第一天起就遵循的设计蓝图。
| 操作系统概念 | Agent 等价物 | 为什么需要 |
|---|---|---|
| 进程 | Agent 实例 | 生命周期管理:启动、运行、中断、快照、恢复 |
| CPU | LLM 模型 | 可替换的推理引擎(Claude / GPT / GLM) |
| RAM(虚拟内存) | 上下文窗口 | 有限资源,需要分级压缩策略 |
| 页面置换算法 | 压缩引擎 | 在信息损失最小的前提下释放上下文空间 |
| 系统调用 | 工具调用 | Agent 与外部世界交互的唯一通道 |
| 中断处理 | Hook 生命周期 | 在关键节点拦截、修改或中止 Agent 行为 |
| 安全 / MAC | 护栏策略 | 权限控制、输入过滤、注入防御 |
| 设备驱动 | 模型 Provider | 不同模型的适配层 |
| 网络栈 | 通道(Channel) | IM / Webhook 适配 |
| 包管理 | Plugin 系统 | 能力扩展与生态复用 |
| IPC | A2A 协议 | 多 Agent 通信 |
| 看门狗 | 熔断器 + 循环检测 | 防止 Agent 失控 |
| 计费系统 | 成本追踪 | Token 用量与费用估算 |
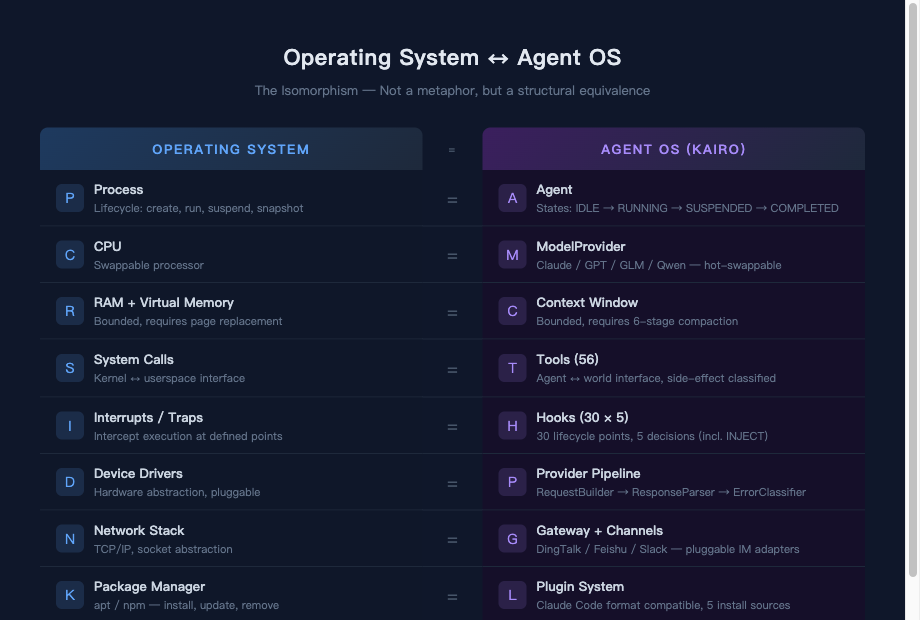
这张表在实际设计中的作用比我预期的要大。每当遇到一个 Agent 运行时的问题,我会先去看操作系统是怎么处理类似场景的。答案不总是能直接套用——Agent 的"内存"是有损的,操作系统的内存是无损的,这一个差别就改变了整套压缩策略的设计。但问题的结构往往是相通的,至少能帮我避开一些前人已经踩过的坑。
这个类比也有它的局限。操作系统管理的是确定性的硬件资源,而 Agent 的"CPU"(LLM)本身就是非确定性的——同样的输入不一定得到同样的输出。这意味着 Agent OS 在调度和容错方面需要做的工作比传统 OS 更多,而不是更少。
为什么是 Java?
一个合理的质疑:既然 Claude Code 用 TypeScript 已经做得很好了,为什么要用 Java 重新构建?
答案不在语言层面,在生态层面。
全球 80% 的企业后端系统运行在 JVM 上。当一家企业想让 Agent 深度集成到现有技术栈——访问内部 API、操作数据库、执行部署管线——它需要的不是一个外部服务,而是一个可以嵌入到现有 Java 应用中的库。
// 这是一个完整的 Agent 应用
Agent agent = AgentFactory.create(config);
Mono<Msg> result = agent.call(Msg.user("重构这个模块"));不需要 Python 虚拟环境,不需要额外的基础设施,不需要学一门新语言。你已经在写 Java 了——现在你的 Java 可以思考、规划和行动。
Kairo 想做的是 Java 生态的 Agent 操作系统。一个完整的运行时——有内存管理,有进程调度,有中断处理,有安全策略,有设备驱动,有包管理。做的是 Claude Code 那 98.4% 的工作,但以 Java 库的形式交付。
代价与诚实
在结束之前,有一个问题必须回答:这值得吗?
复刻 Claude Code 级别的运行时基础设施意味着巨大的工程量。Kairo 框架目前有 31 个 Maven 模块,30 个架构决策记录(ADR),超过 2,500 个测试。中间有好几次我怀疑自己是不是在造一个没人需要的东西。
而且模型在持续变强。也许有一天,模型本身就能完美管理上下文、检测循环、防御注入。到那时,今天这些基础设施就多余了。
但"也许有一天"不是今天。今天一个 30 步的 Agent 端到端成功率是 4.2%,没有上下文压缩的 Agent 在第三个文件就会失忆,没有循环检测的 Agent 会在同一个错误上烧掉 $200 的 token。
正如操作系统之所以存在,是因为硬件不完美——CPU 会中断,内存会不足,外设会失败。如果硬件完美了,谁还需要操作系统?但硬件从来没完美过,模型大概率也不会。所以 Agent 需要一个操作系统。
而这个系列,就是这个操作系统的设计笔记。
下一篇:《上下文是有限的——Agent 的内存管理问题》
参考
- VILA-Lab, "Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems," arXiv:2604.14228, April 2026
- DuoCode Technology Blog, "The Harness That Makes the Model Useful: A Source-Level Study of Claude Code," March 2026
- tangweigang-jpg/Claude-code-research, "14-Chapter Deep Architecture Analysis," GitHub, April 2026
- AICatchup, "Codex CLI vs Claude Code vs Cursor: 2026 Architecture Deep-Dive," April 2026
- amux.io, "Background Coding Agents Compared: Cursor vs Claude Code vs Devin vs Copilot vs Codex," May 2026